01
Open the settings module
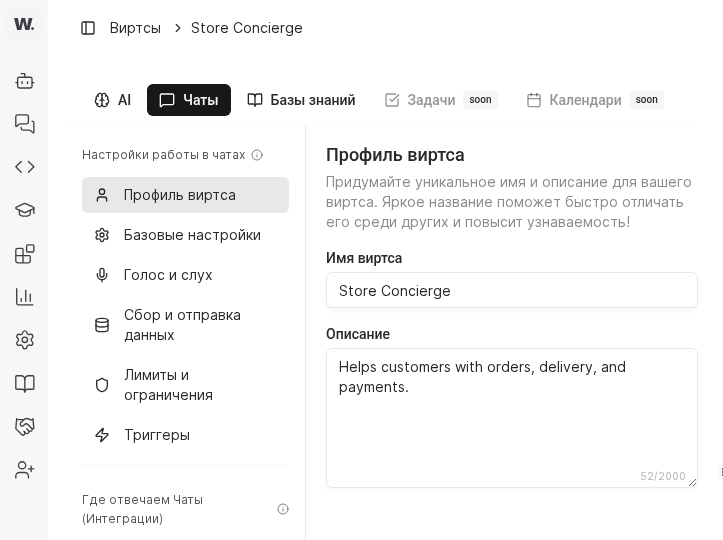
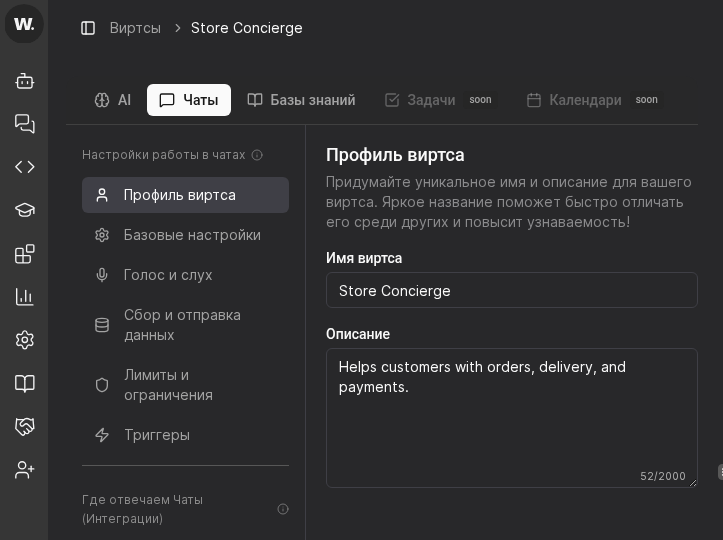
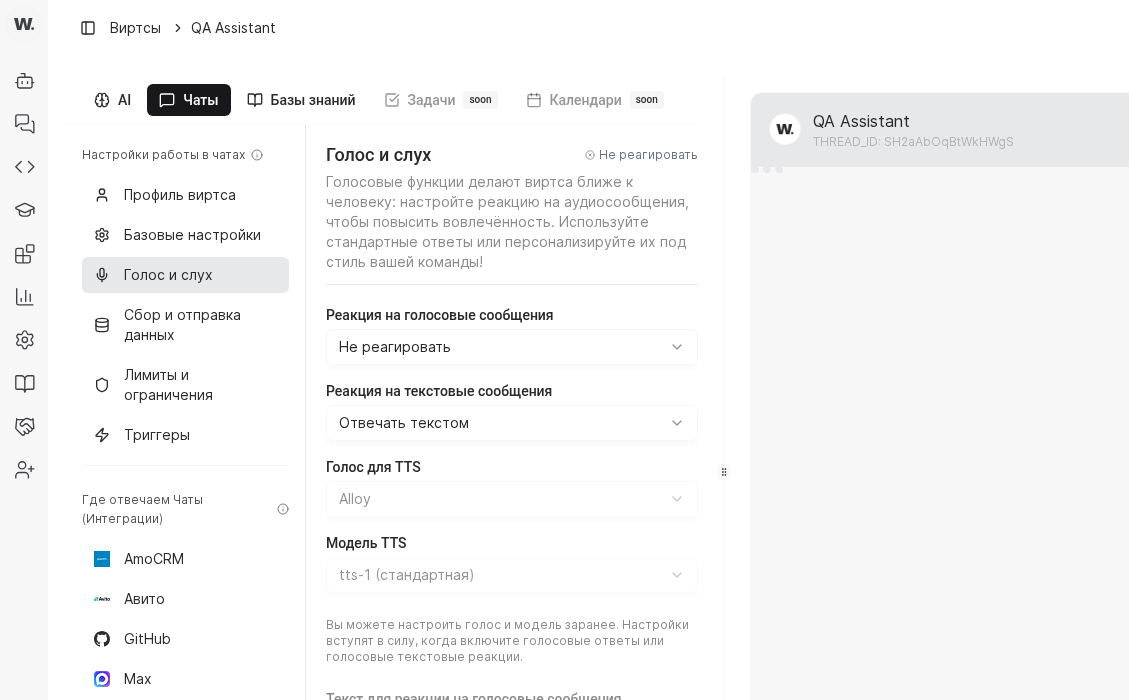
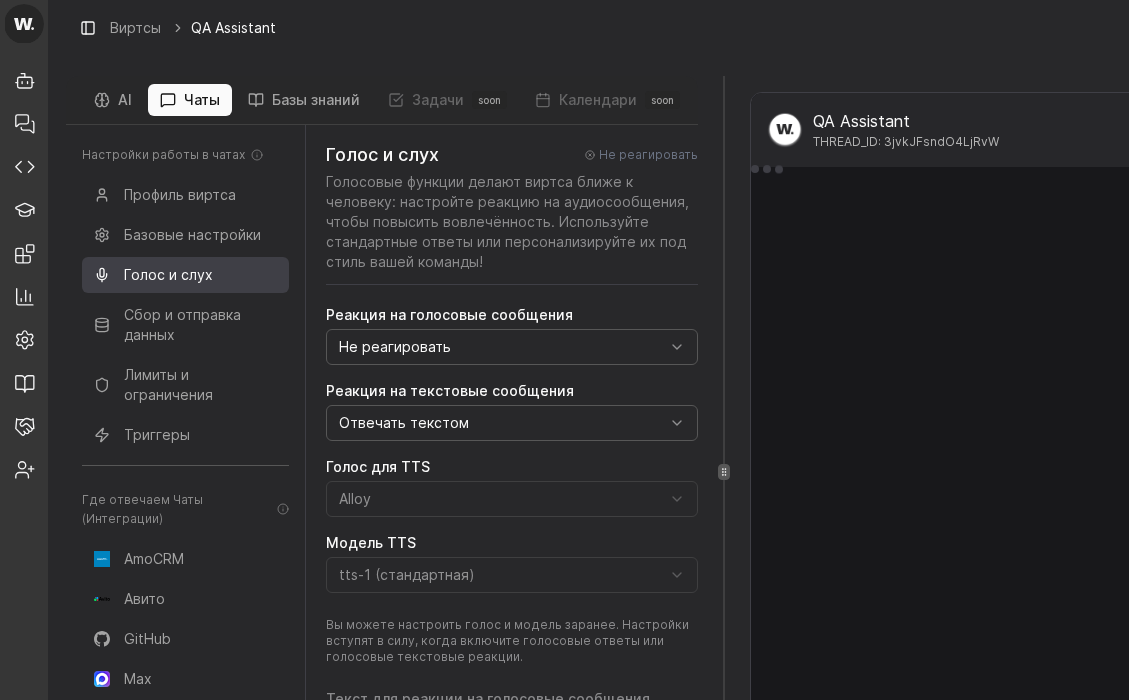
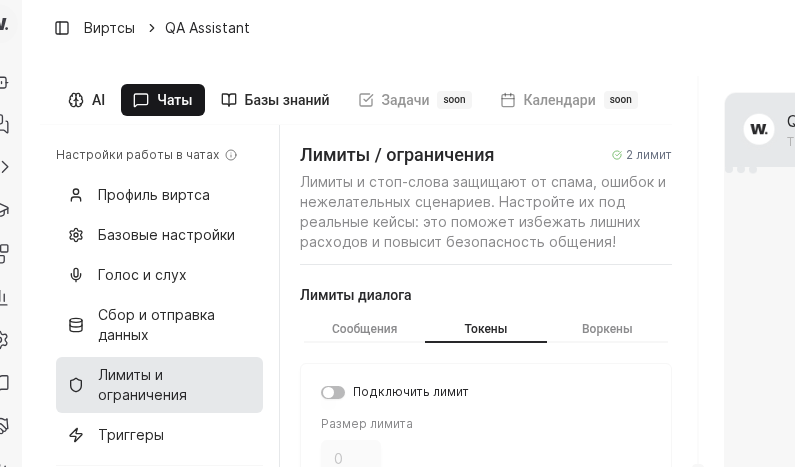
- Open the target virt card and switch to the “Chats” tab.
- Confirm the screen shows “Настройки работы в чатах” and the “Профиль виртса” section.
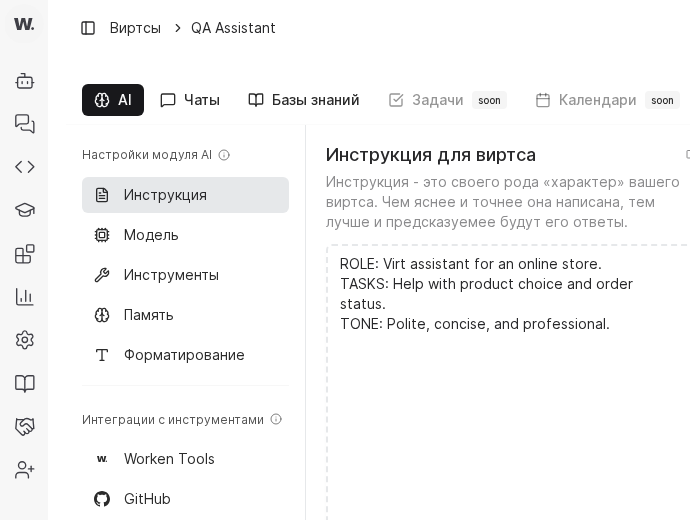
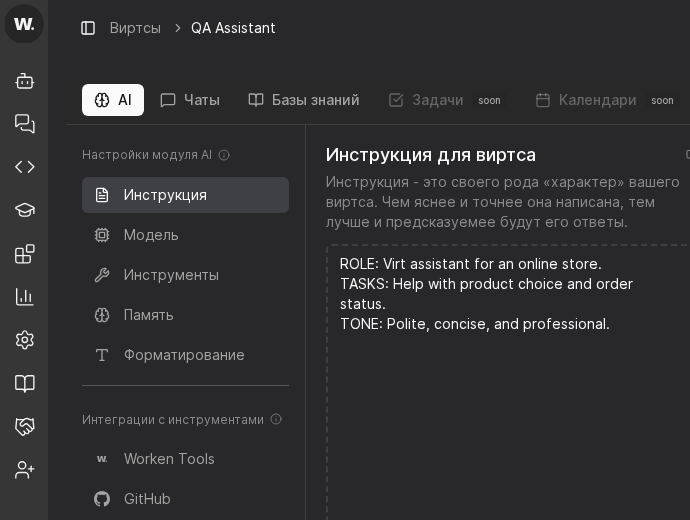
- Use top tabs “AI” and “Чаты” to move between system instructions and chat settings.