01
Откройте карточку конфигурации
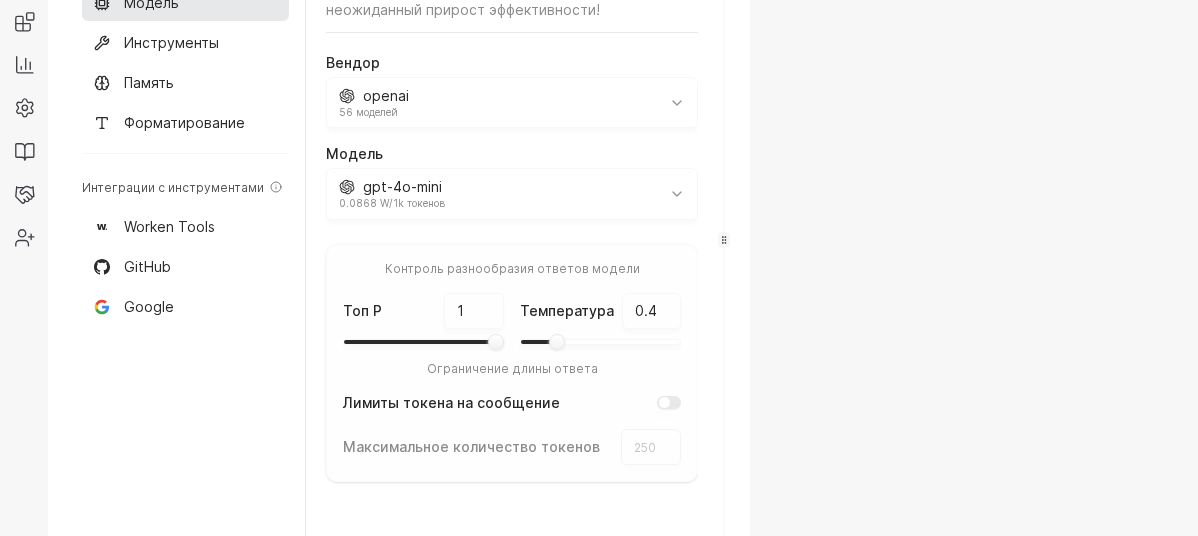
Выберите нужного виртса, перейдите во вкладку AI и кликните секцию Модель. Убедитесь, что открыт нужный виртс и видны блоки выбора вендора и модели перед изменением параметров.

Выбор модели влияет на скорость, тон и стоимость ответа виртса. Эта страница помогает быстро настроить параметры под конкретный сценарий.
Перед началом
Выберите нужного виртса, перейдите во вкладку AI и кликните секцию Модель. Убедитесь, что открыт нужный виртс и видны блоки выбора вендора и модели перед изменением параметров.
В выпадающем списке выберите нужного вендора: OpenAI или GigaChat подходят для большинства консультаций, DeepSeek и Anthropic удобны для длинного контекста. Сохраните выбор и сразу убедитесь, что подключенные ключи прошли проверку.
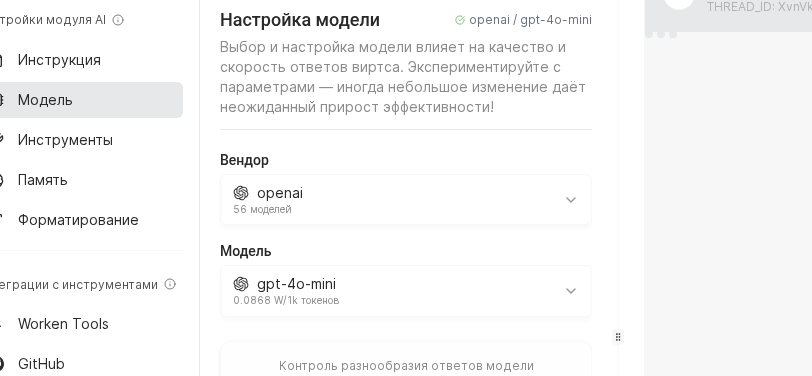
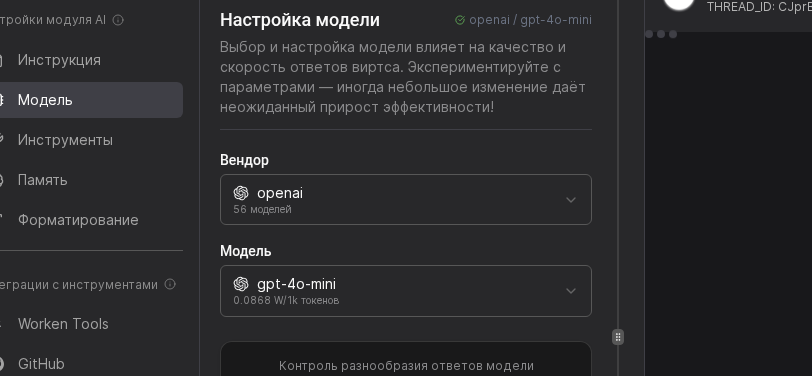
Сдвиньте ползунок Температура к 0.3 для строгих ответов либо к 0.9 для более дружелюбной речи. Ниже задайте ограничение токенов: 700 подходит для чатов поддержки, 1500 для консультаций с длинными выдержками.
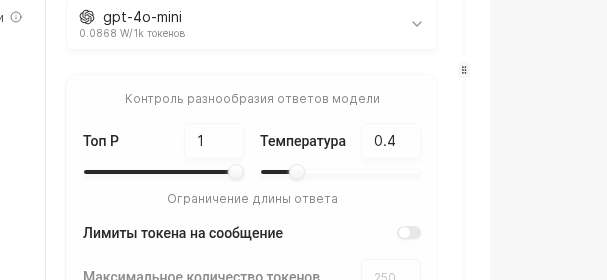
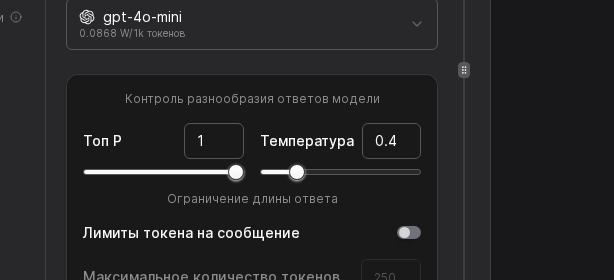
Проверьте связку Вендор + Модель, затем ещё раз оцените Температуру, Top P и лимит токенов. При необходимости скорректируйте значения и нажмите Сохранить.
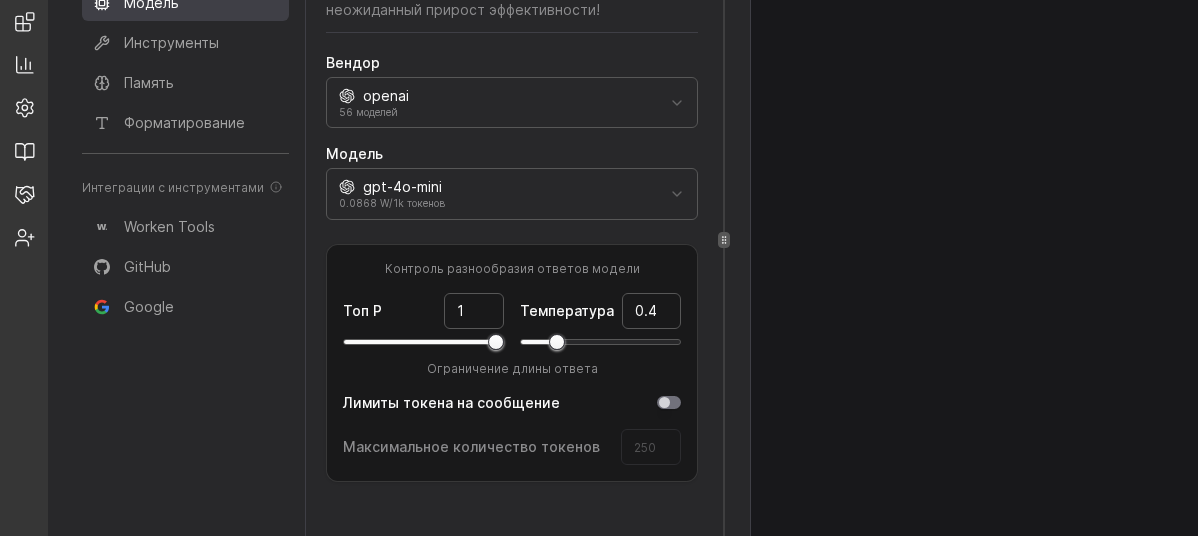
Предупреждение
Если токены заканчиваются быстрее ожиданий, сначала снижайте лимит контекста и только потом переключайте модель, так проще сравнить результаты.
Пример
Сеть служб доставки использует GigaChat для русскоязычных заказов. Модель настроена на температуру 0.4 и лимит 900 токенов, чтобы ответы были короткими и точными. После внедрения команда увидела, что стоимость диалога снизилась на 18 процентов, а первый ответ стал появляться на 2 секунды быстрее.